Chat with BC Laws
Technical presentation
Focused on search
indexing data and retrieval
- Knowledge Graph
- Local search (basic RAG)
- Multi-modal search
- Global search
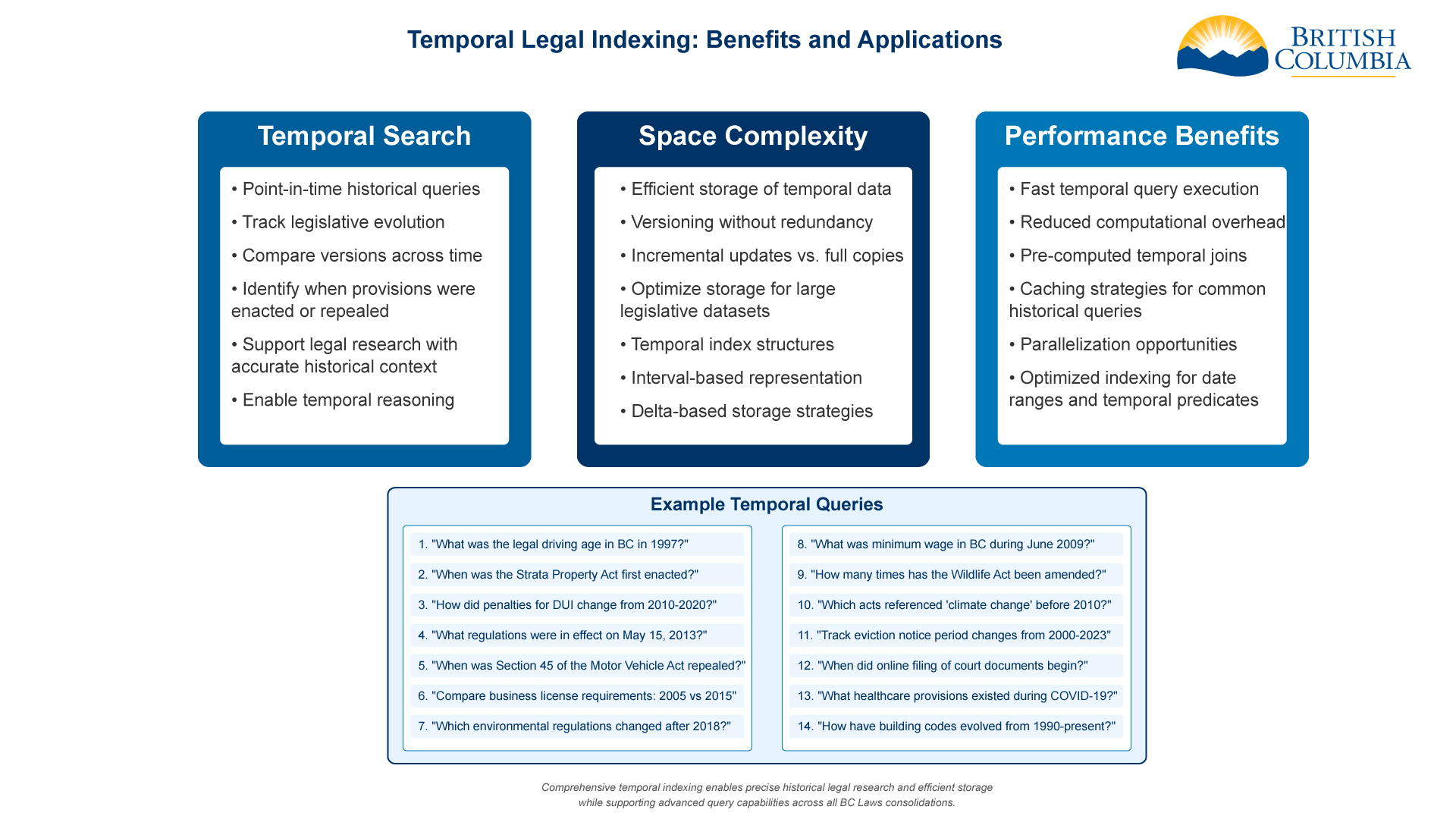
- Temporal search
Our Priorities
- Optimize to run everything in OpenShift or hybrid
- Using small embedding models
- Keeping cost low
- Control of our data
- No vendor lock-in
What we will cover
- Architecture
- HMVC Backend Transformation
- Text Indexing
- Multi-modal Indexing
- Temporal Indexing
- MLOps & Analytics
- AI Model Training
- Public Cloud
- Challenges
- Q&A
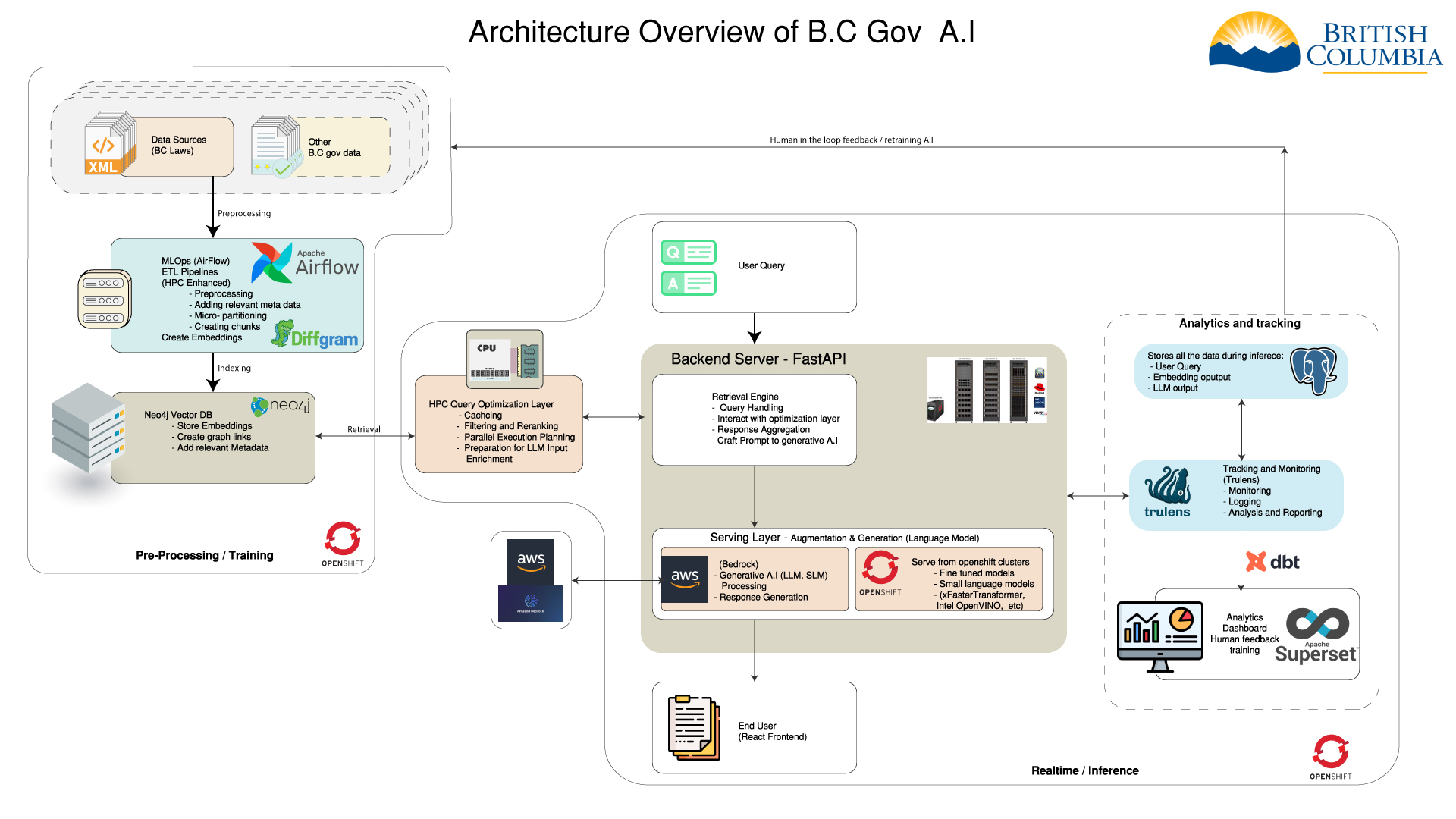
Architecture
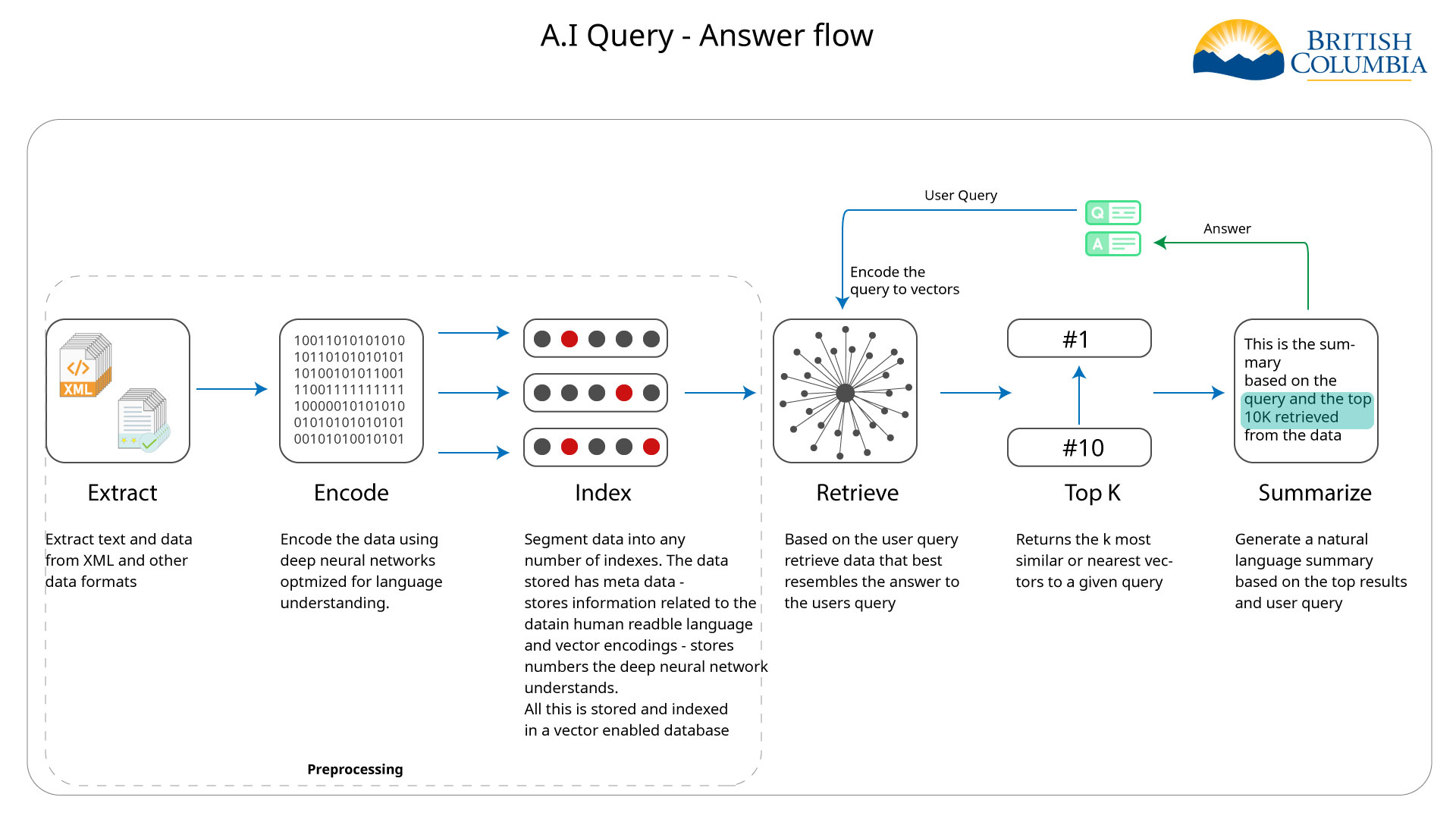
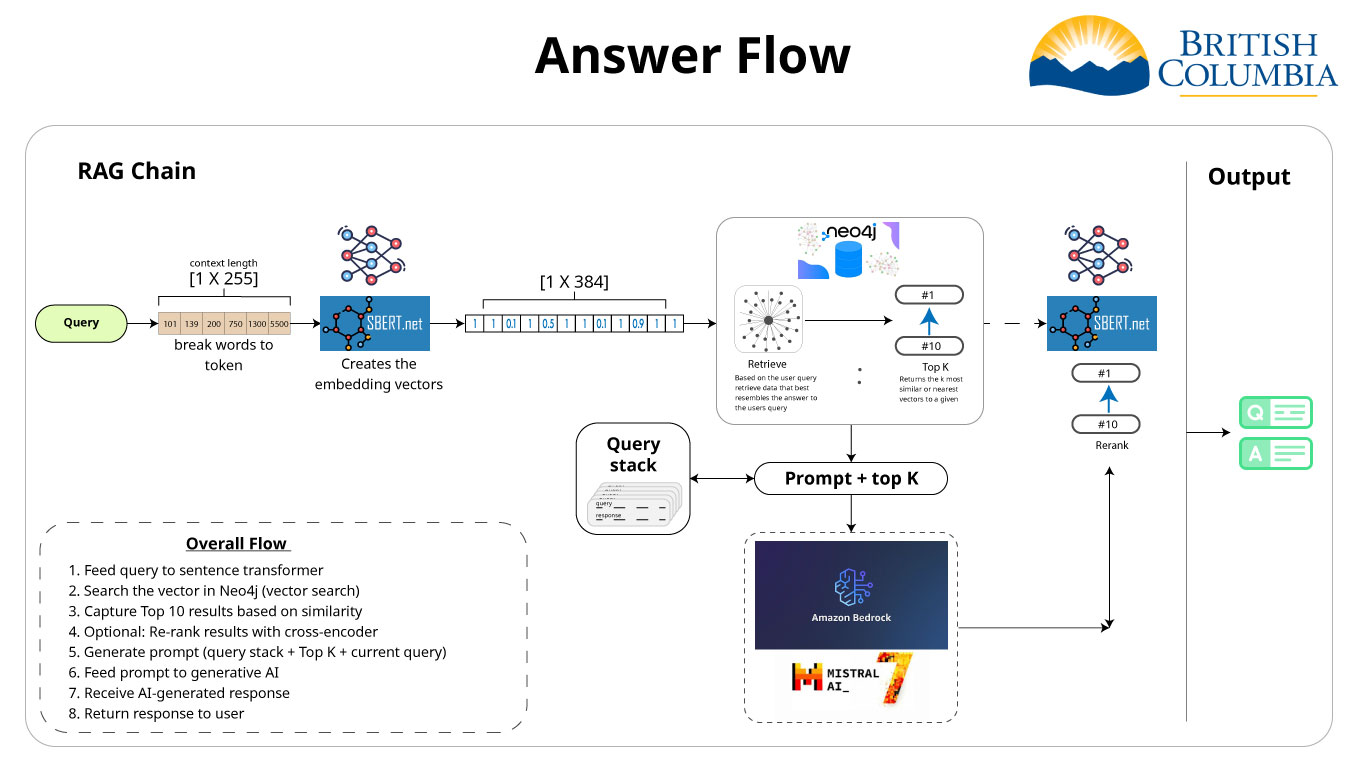
RAG Pipeline
- Feed query to sentence transformer
- Search the vector in Neo4j (vector search)
- Capture Top 10 results based on similarity
- Optional: Re-rank results with cross-encoder
- Generate prompt (query stack + Top K + current query)
- Feed prompt to generative AI
- Receive AI-generated response
- Return response to user

HMVC Backend Transformation
From Monolithic to Modular Architecture
Why HMVC? The Challenge
- Growing complexity in FastAPI backend
- Feature coupling causing breaking changes
- Multiple developers stepping on each other's work
- Difficult to test individual features
- Scaling concerns with new feature additions
Traditional MVC vs HMVC
Traditional MVC
app/
??? controllers/
? ??? login.py
? ??? chat_RAG.py
? ??? agent.py
? ??? analytics.py
? ??? feedback.py
??? models/
? ??? user.py
? ??? chat.py
? ??? analytics.py
??? views/
??? responses/HMVC Architecture
app/modules/
??? auth/
? ??? controllers/
? ??? models/
? ??? views/
? ??? services/
??? chat/
? ??? controllers/
? ??? models/
? ??? views/
? ??? services/
??? [other modules...]Module Breakdown
- Authentication Module: User login, token management, session validation
- Chat Module: RAG processing, conversation management, TruLens integration
- Agent Module: MCP agent orchestration, multi-agent coordination
- Analytics Module: Usage tracking, session analytics
- Feedback Module: User feedback collection and processing
Why HMVC is Essential for Agent Systems
As AI systems become more complex, architectural changes become necessary:
- Agent Isolation: Each agent type has distinct capabilities and requirements
- Independent Development: Developers can work on specialized functionality without conflicts
- Scalable Orchestration: Complex multi-agent workflows require modular architecture
- Future Agent Types: Easy to add analysis, specialized, or domain-specific agents
Agent Architecture Benefits
The modular approach enables sophisticated agent coordination:
- Hierarchical Structure: Orchestrator agents can coordinate multiple specialized agents
- Capability Tracking: System maintains registry of what each agent can accomplish
- Error Isolation: Agent failures are contained within their modules
- Independent Testing: Each agent can be tested in isolation with mock dependencies
- Resource Management: Different agents can have different computational requirements
app/modules/agent/agents/
??? orchestrator/ # High-level coordination
??? search/ # Search capabilities
??? analysis/ # Future analysis agents
??? specialized/ # Domain-specific agentsBenefits Realized
Development Efficiency
- Developers can work on separate modules independently
- Faster feature development cycles
- Parallel development workflows
Maintainability
- Issues isolated to specific modules
- Easier debugging and testing
- Cleaner, more organized code structure
- Simplified dependency management
Testing
- Reduced test complexity
- Independent module testing
- Better test isolation and coverage
Scalability
- Easy to add or remove modules
- Modules can become microservices
- Infrastructure can scale per module needs
Deployment Flexibility
- Modules can be separated into individual containers
- Easy pickup and drop-in for container orchestration
- Independent deployment and scaling per module
HMVC Transformation Summary
Key Achievements
- Transformed monolithic MVC into feature-based HMVC modules
- Built foundation for complex multi-agent AI workflows
- Enabled parallel development with reduced conflicts
- Designed modules for easy container separation
What This Enables
- Independent agent development and deployment
- Sophisticated AI orchestration capabilities
- Flexible infrastructure scaling per module
- Improved developer experience and maintainability
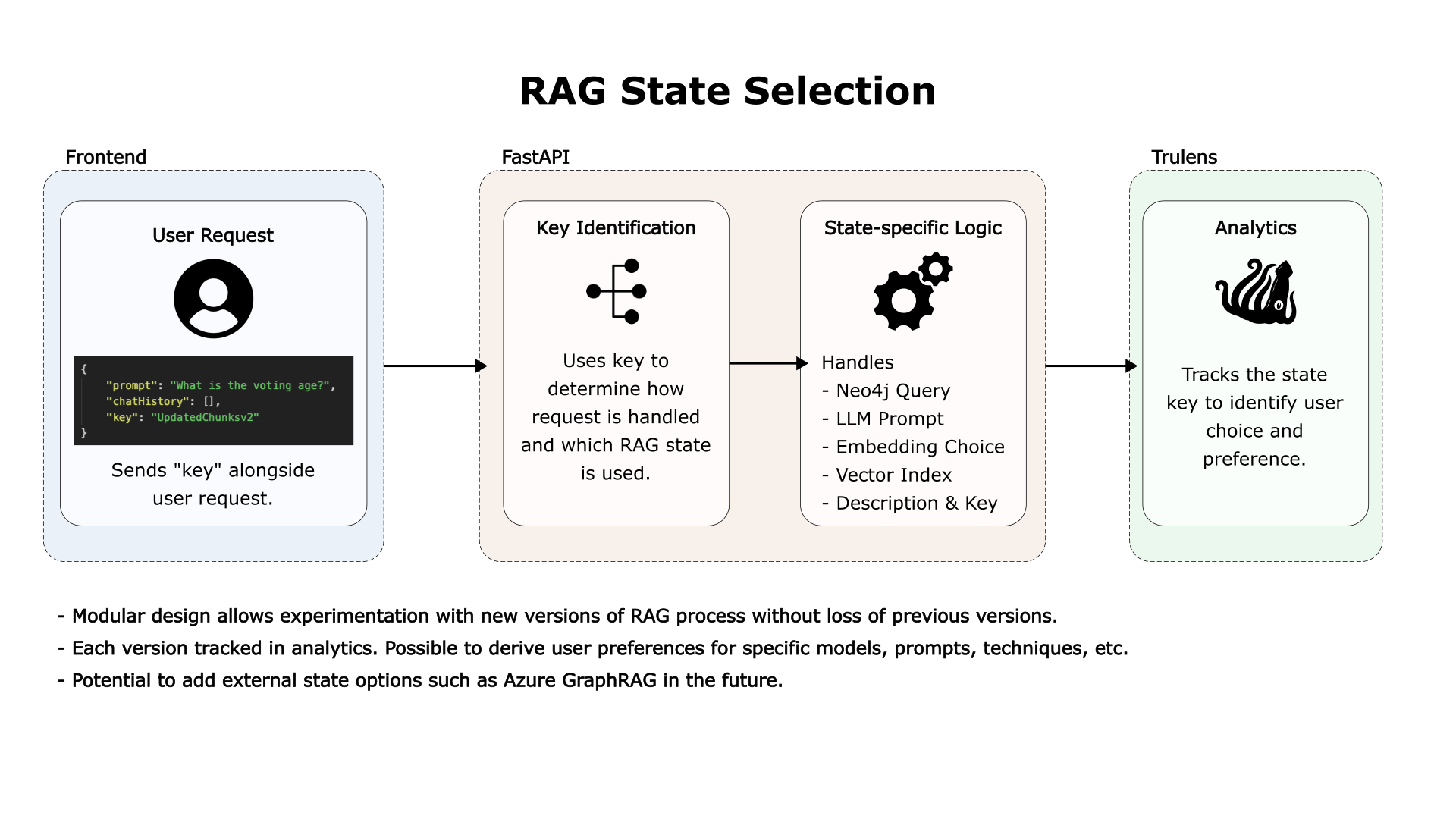
Navigating the Complexities of Legislative Indexing
How we index the acts and regulations

How data is stored in Neo4j
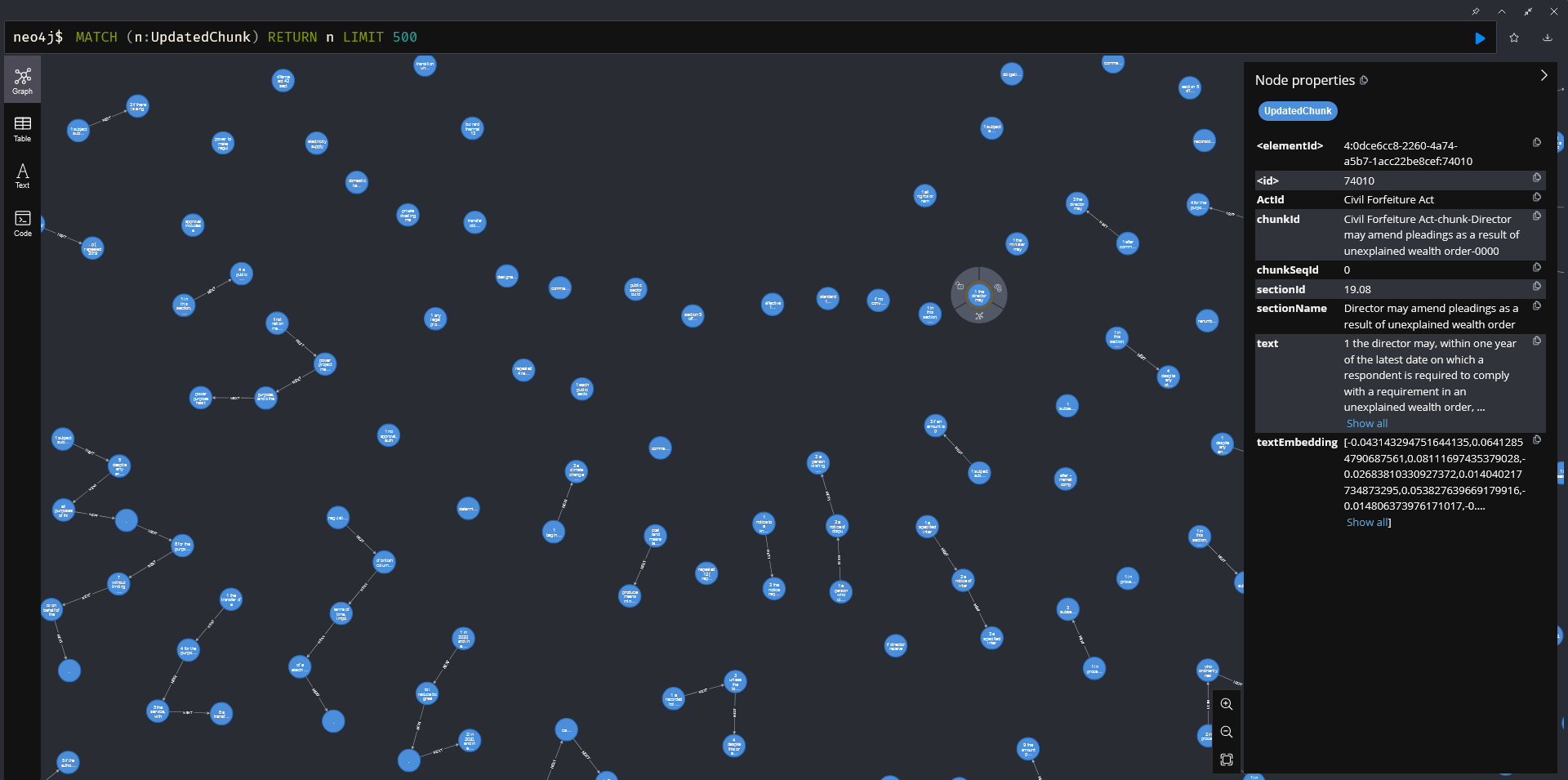
Graph Database and vector store
| Data storage | Neo4j Integration | Advanced Querying |
|---|---|---|
| We use a graph database to store the data. | Neo4J is leveraged for both the graph database and the vector store. | Neo4J enables advanced queries, such as clustering the data and finding communities. |
| Vector store is utilized for storing embeddings. | These tasks are more efficient and easier to implement using a graph database. |
Atomic Indexing
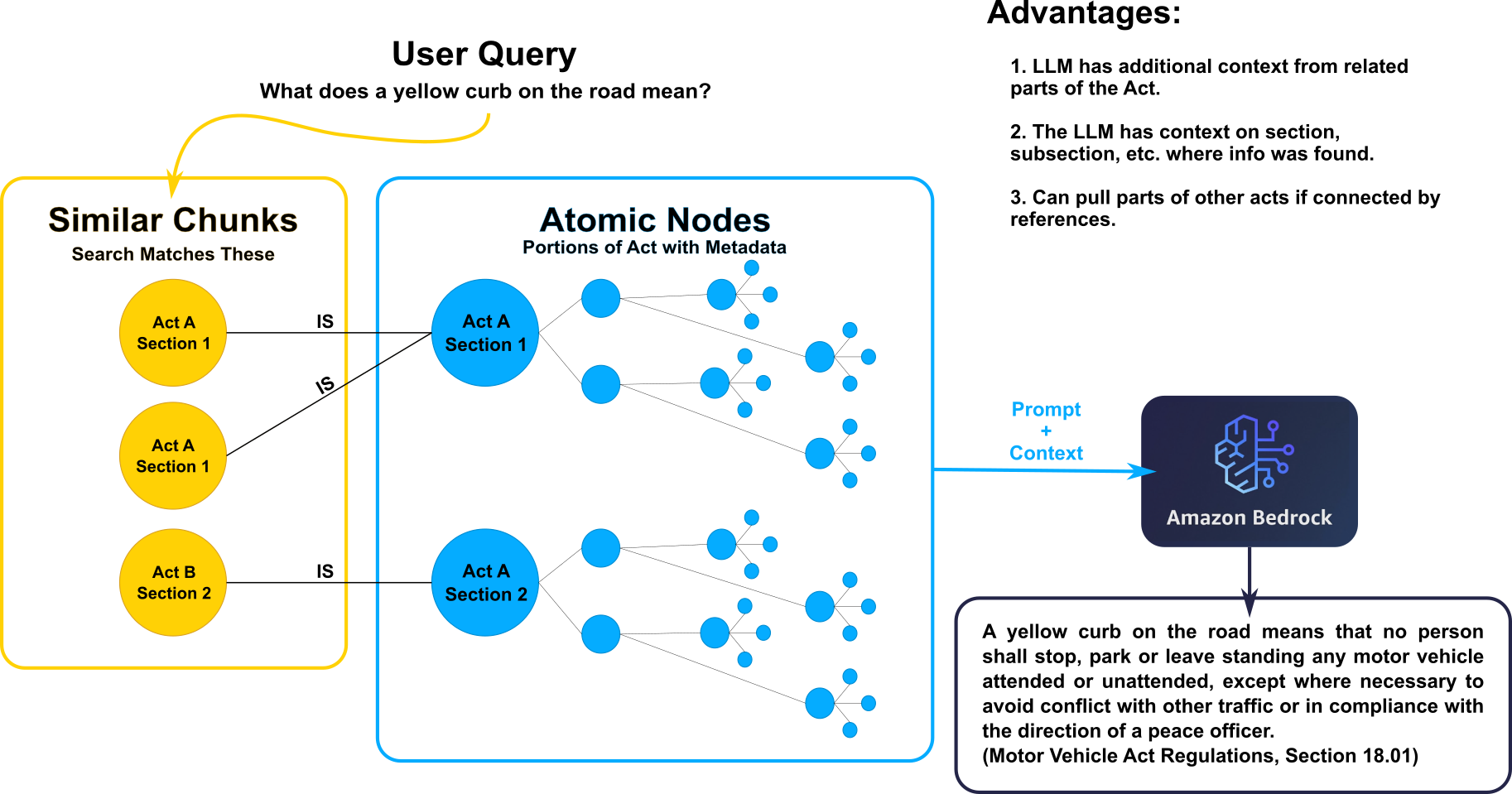
- Breaking down indexed data in a way that reflects structure of laws: Acts contain Sections, which may contain Subsections, etc.
- Adding important metadata as context provided to LLM
- Including citations in LLM responses.
e.g. (Motor Vehicle Act, Section 1 (2)(a))
Atomic Indexing Process
- Break down XML documents based on element name and construct objects for each element
- Insert these elements into the database and connect them to their parent and child elements
- Connect atomic sections with UpdatedChunk sections using the [:IS] relation edge
Atomic Indexing Example
Indexing Images
Making legal document images fully searchable
- Image Retrieval & Processing
- AI-Based Image Summarization
- Model Comparison: Open-Source vs Cloud
- Vector Database Indexing
Image Retrieval & Processing
Retrieval Process
- Extraction from BC Laws site
- Hierarchical organization by image type
- Custom path-based metadata extraction
Processing Steps
- Base64 encoding for API compatibility
- Image context preservation
- Metadata tracking for traceability
AI-Based Image Summarization
Standardized Prompt Structure
- Image type & category classification
- Document context extraction
- Content element identification
- Structural component analysis
- Technical specification documentation
Consistent prompt design ensures standardized extraction across models
Model Comparison: Infrastructure
| Feature | MOLMO 7B | Amazon Nova Pro | Claude 3.5 Sonnet |
|---|---|---|---|
| Deployment | Self-hosted (OpenShift) | AWS Bedrock | AWS Bedrock |
| Parameters | 7 Billion | Proprietary | Proprietary (175B+) |
| Processing Time | 15-20 sec/image (~ 24 hours) |
2-3 sec/image (~ 3-3.5 hours) |
2-4 sec/image (~ 3-3.5 hours) |
| Input Cost | Free (self-hosted) | $0.0008/1K tokens | $0.003/1K tokens |
| Output Cost | Free (self-hosted) | $0.0032/1K tokens | $0.015/1K tokens |
| Total Cost (4459 images) |
Free | ~$20 | ~$60 |
Model Comparison: Performance
| Aspect | MOLMO 7B | Amazon Nova Pro | Claude 3.5 Sonnet |
|---|---|---|---|
| Content Accuracy | Moderate | Good | Excellent |
| Prompt Following | Inconsistent | Variable | Highly consistent |
| Output Structure | Often deviates | Sometimes deviates | Follows structure precisely |
| Legal Domain | Basic understanding | Good understanding | Strong contextual grasp |
| Overall Quality | Acceptable | Good | Superior |
Why We Chose Claude 3.5 Sonnet
Key Decision Factors
- Superior prompt adherence
- Consistent structured output
- Better recognition of legal elements
- Higher accuracy on technical content
Cost-Benefit Analysis
- Higher token cost offset by improved quality
- Reduced need for manual corrections
- Better downstream search performance
- Substantially faster than OpenShift solution
Structured JSON Storage
{
"Acts": {
"Election Act": {
"96106_greatseal.gif": "1. Image Type and Category...",
// More images...
},
// More acts...
},
"Regulations": {
"Wildfire_Regulation___38_2005": {
"38_2005.gif": "1. Image Type and Category...",
// More images...
}
}
}Structured JSON Storage Benefits
- Preserves document hierarchy
- Maintains original context
- Enables incremental updates
- Simplifies downstream processing
Vector Database Indexing
Key Components
- Text Chunking: 256 tokens with 20 token overlap
- Embeddings: all-MiniLM-L6-v2 (384 dimensions)
- Node Labels: ImageChunk, UpdatedChunksAndImagesv4
- Relationships: NEXT (sequential), PART_OF (document)
- Metadata: Source path, document type, file references
Lessons Learned
- Larger models dramatically improve content extraction quality
- AWS Bedrock enables rapid iteration and production scaling
- Standardized prompts are critical for consistent results
Lessons Learned Cont.
- Costs for Claude 3.5 Sonnet are justified by reduction in post-processing
- Chunking with relationships preserves critical context
- Integration pipeline enables comprehensive image search
Future Directions
- Evaluate additional specialized models for niche content
- Implement automated image change detection
- Optimize chunking based on content characteristics
- Enhance handling of complex tables and forms
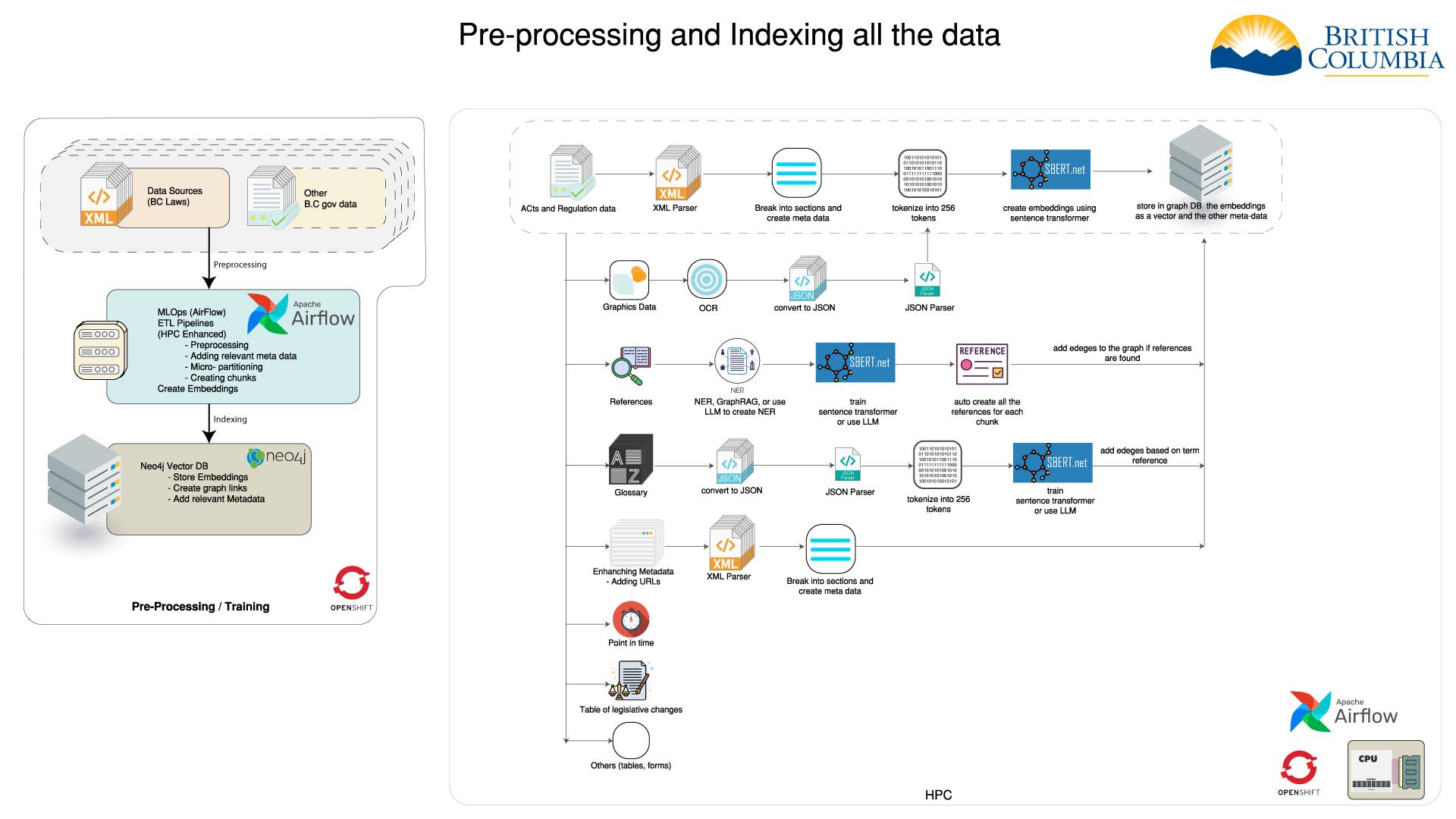
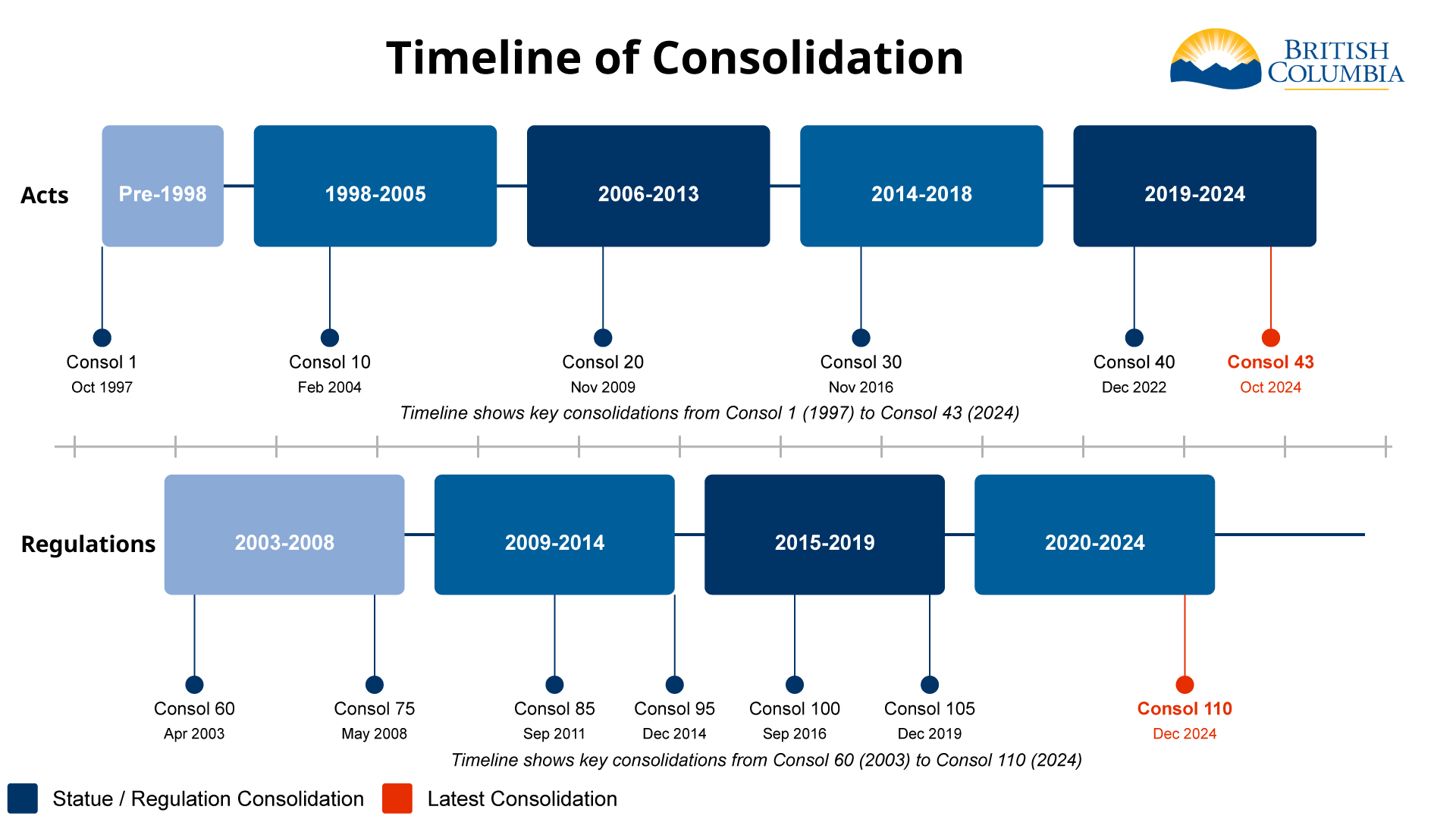
Indexing all the consolidations
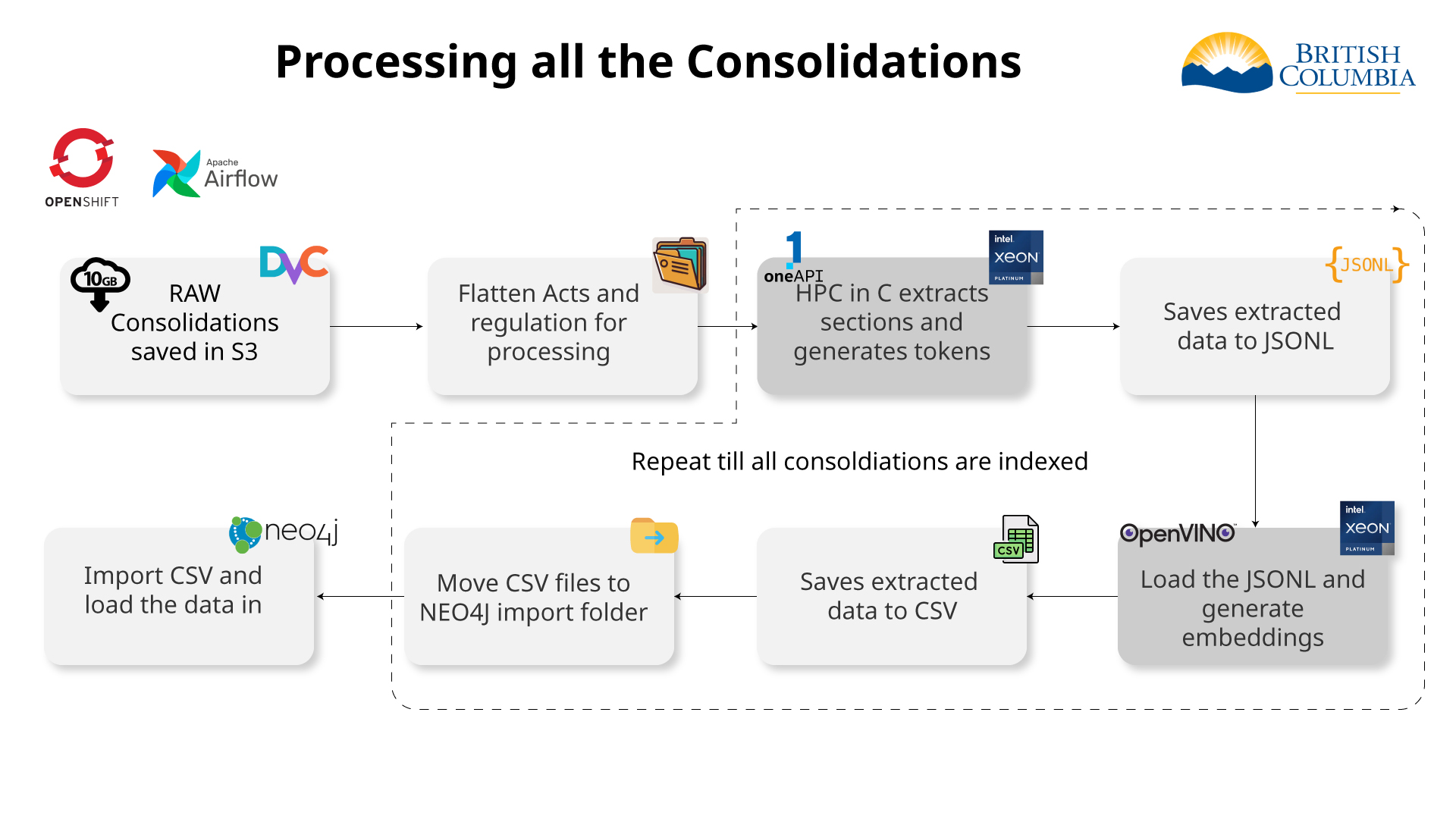
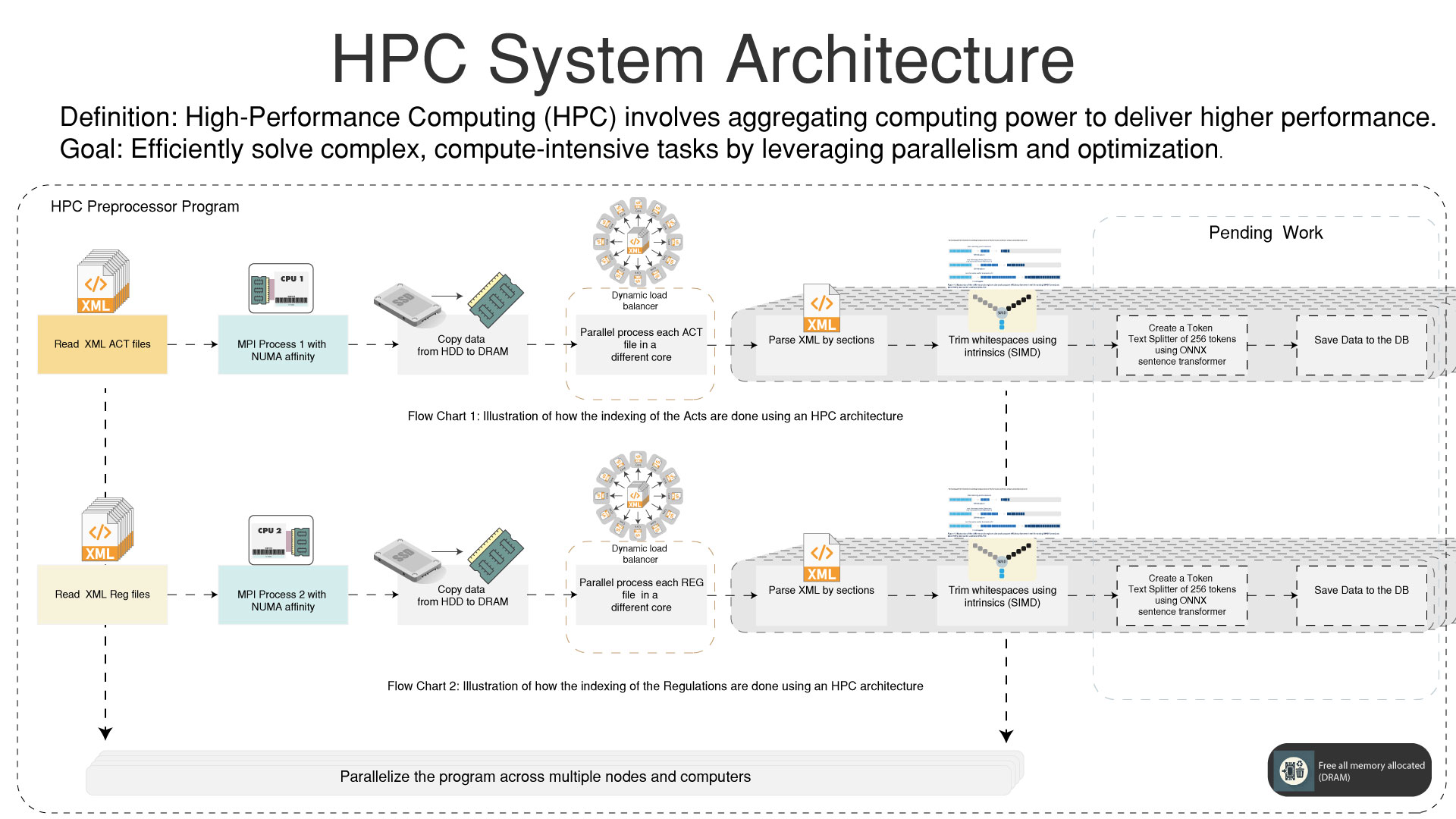
HPC
High Performance Computing for pre-processing the data
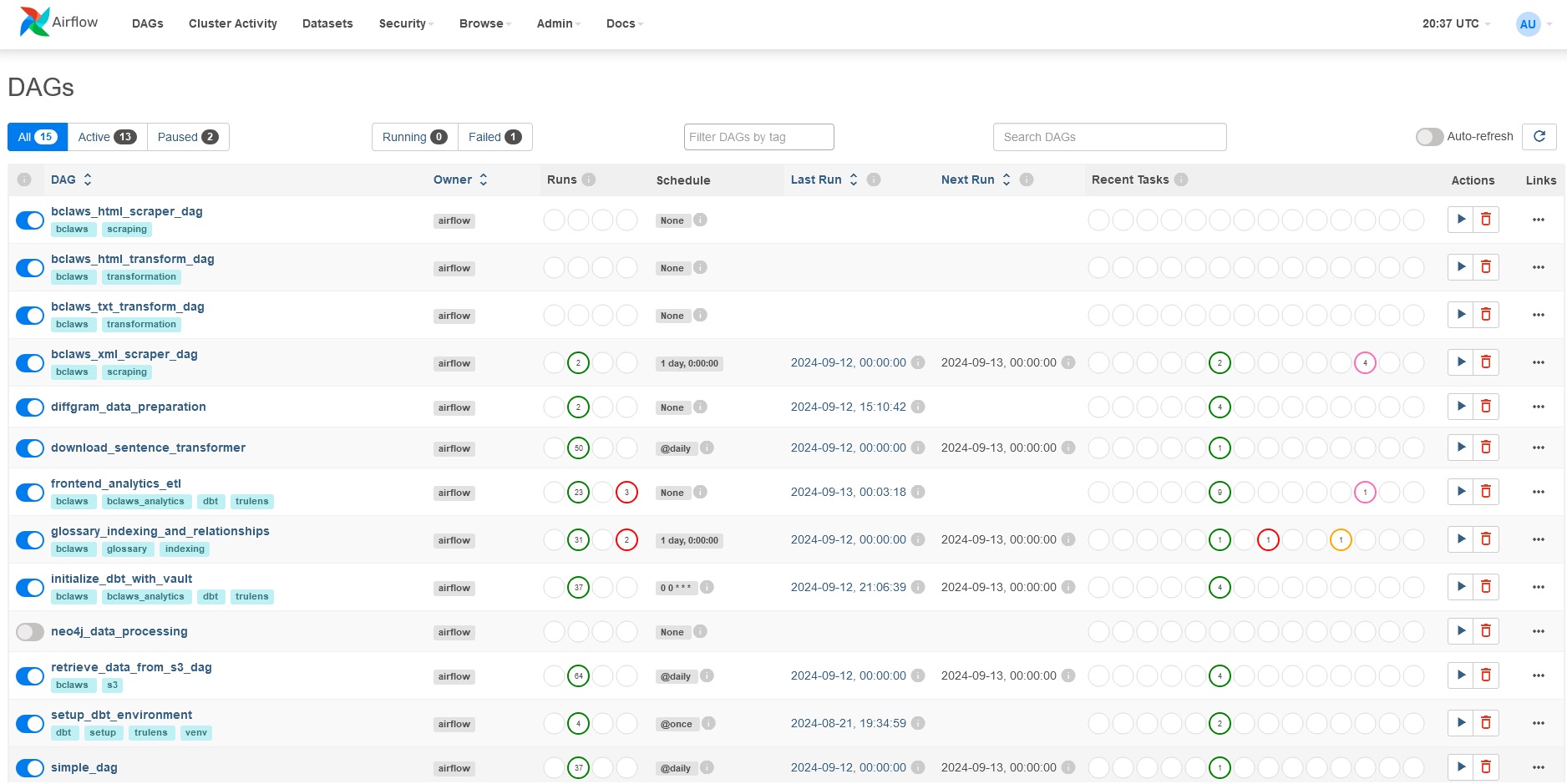
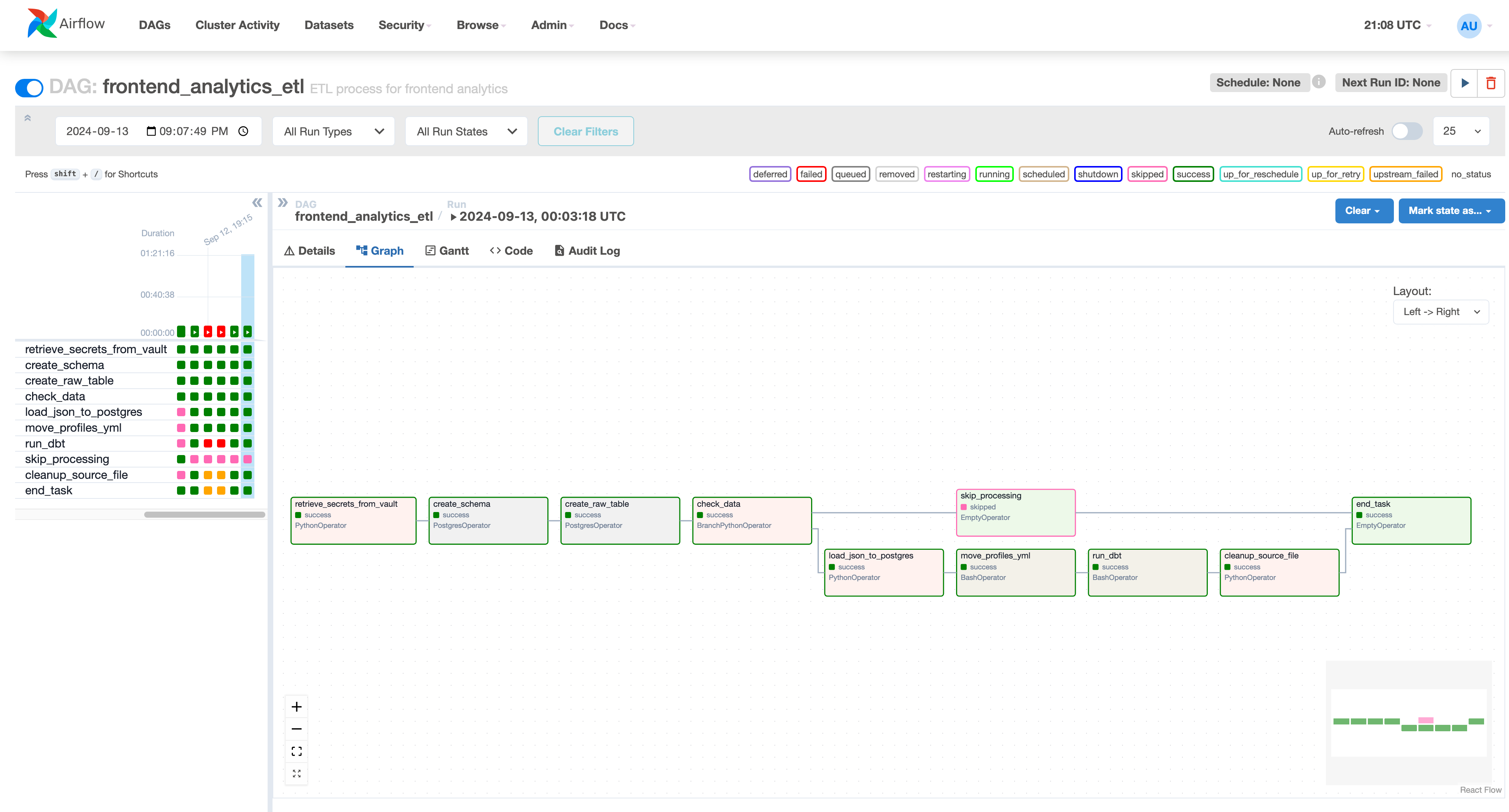
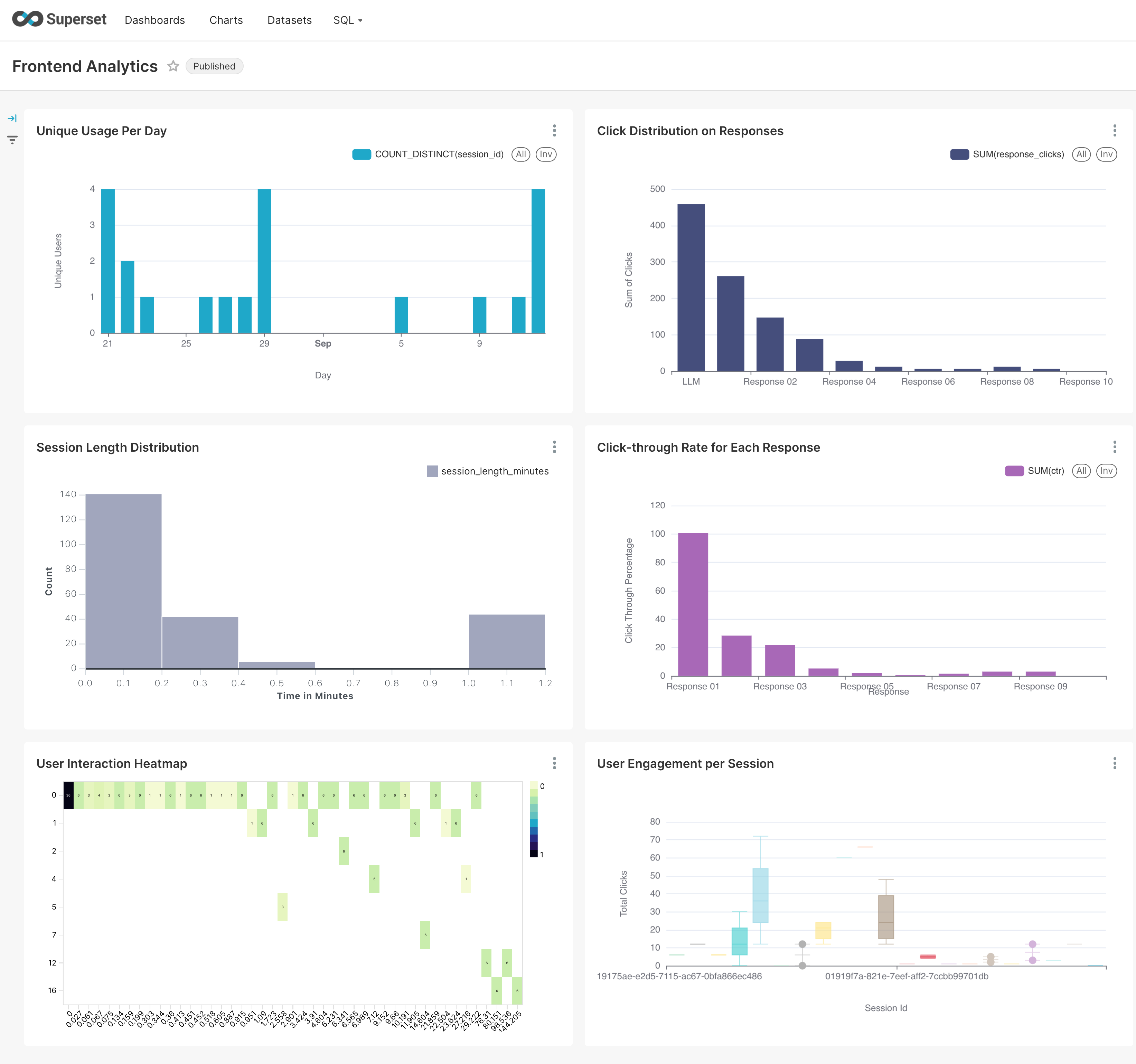
MLOps & Analytics
- Frontend analytics data
- Backend RAG Chain tracking
- Apache Airflow for orchestration
- dbt for data transformation
- Integration with active learning pipeline
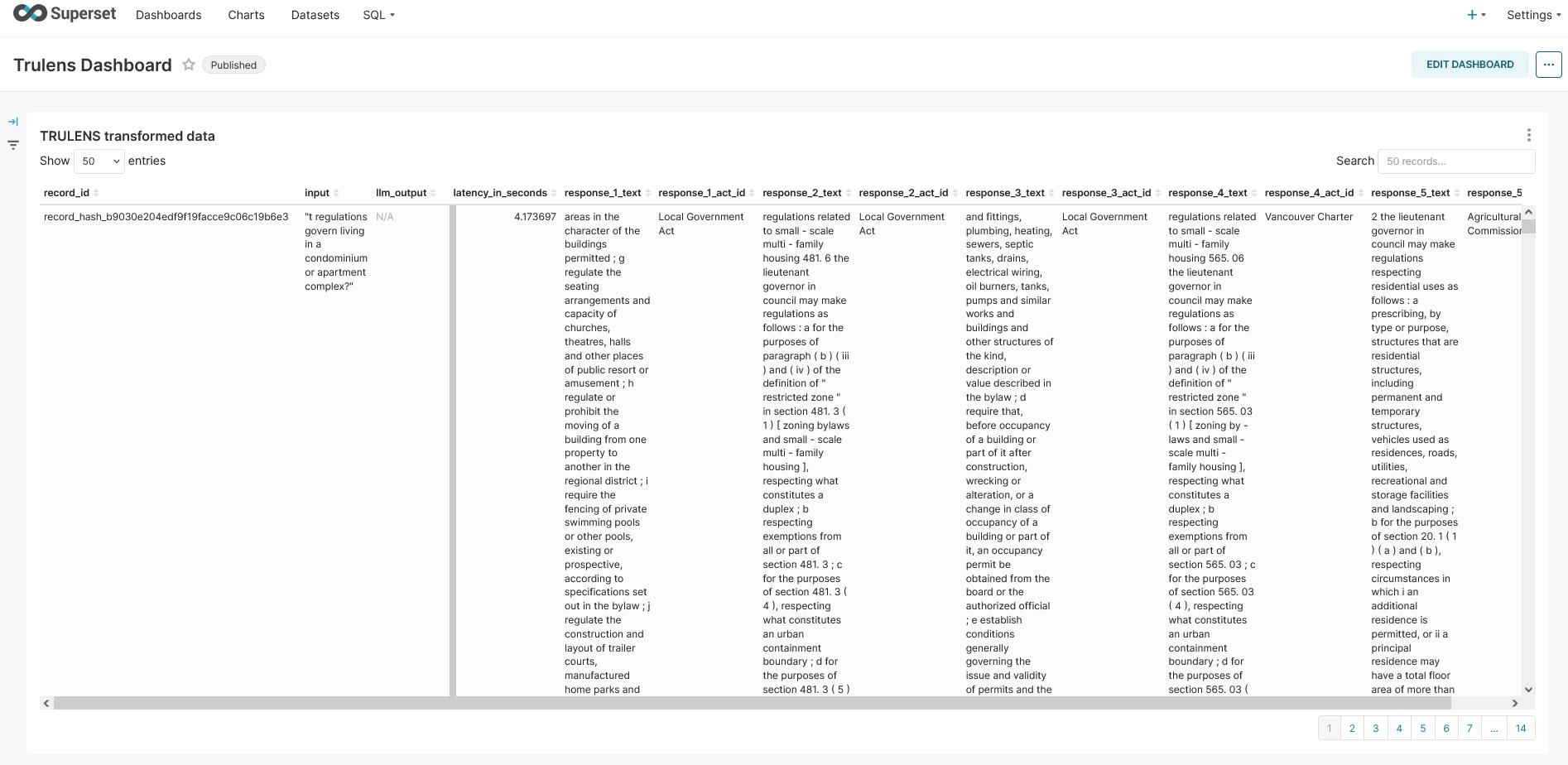
Active Learning Integration
- Analytics data feeds into active learning pipeline
- Helps identify areas for model improvement
- Informs data selection for model fine-tuning
- Enables continuous improvement of the AI system
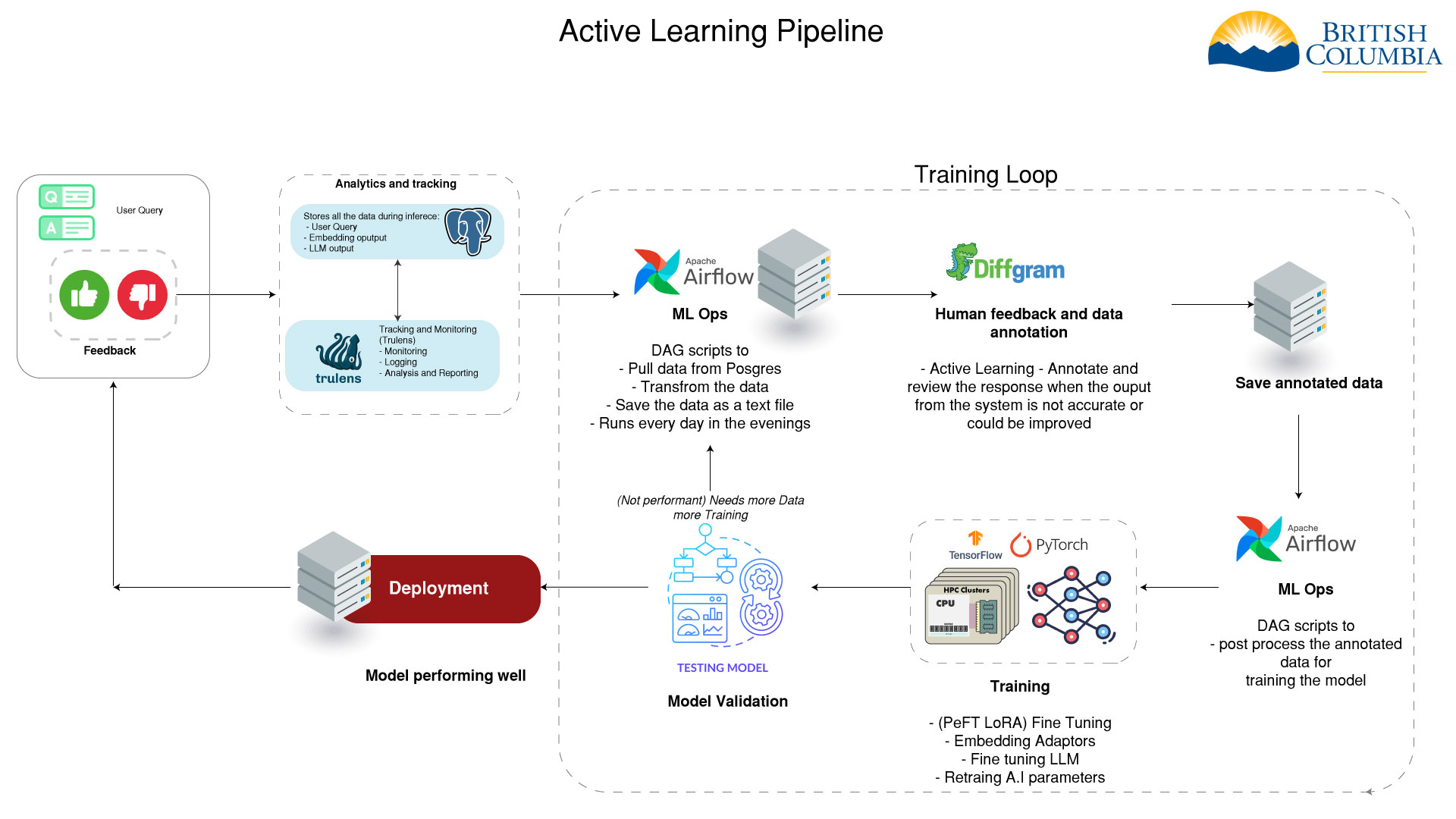
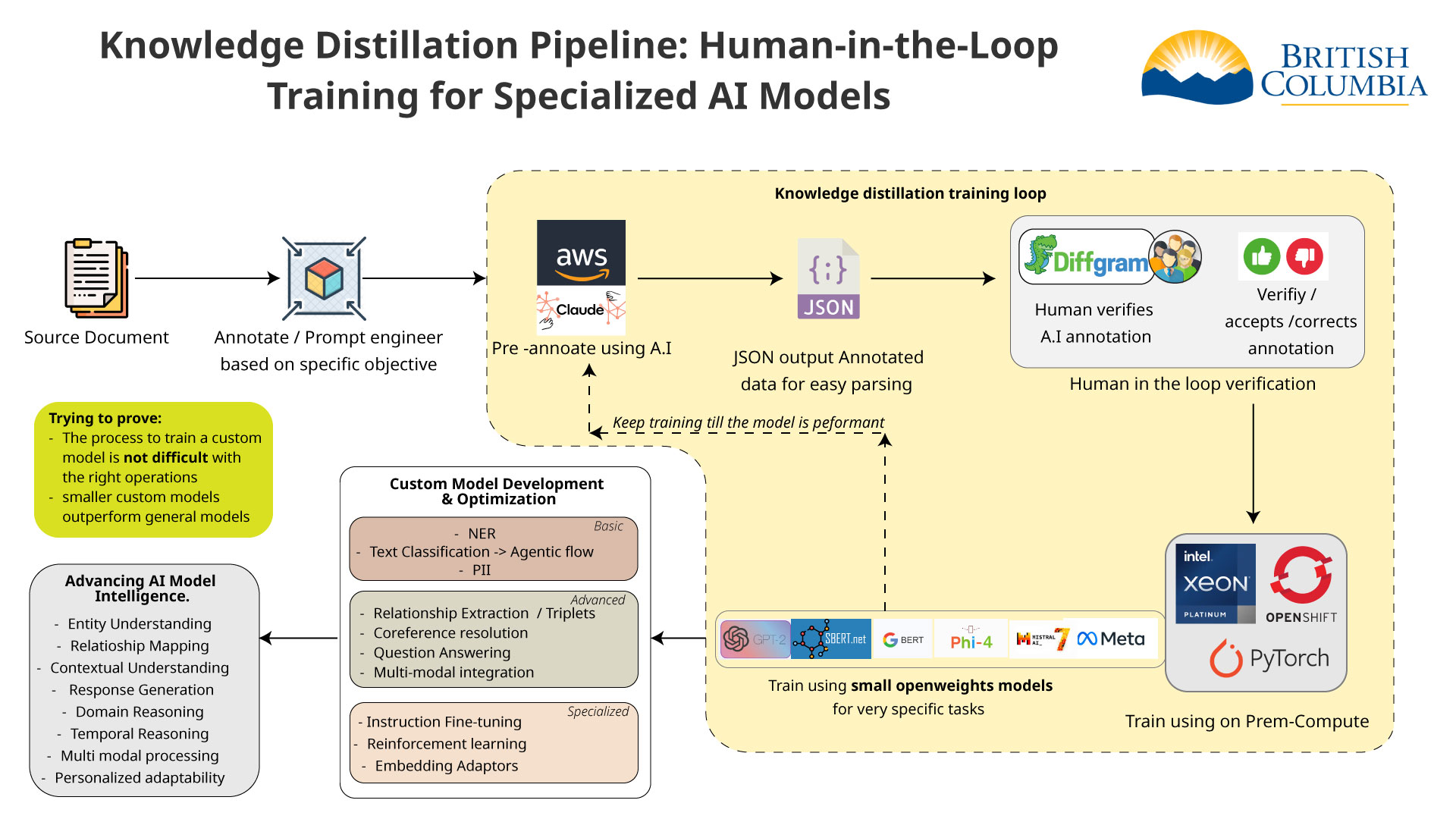
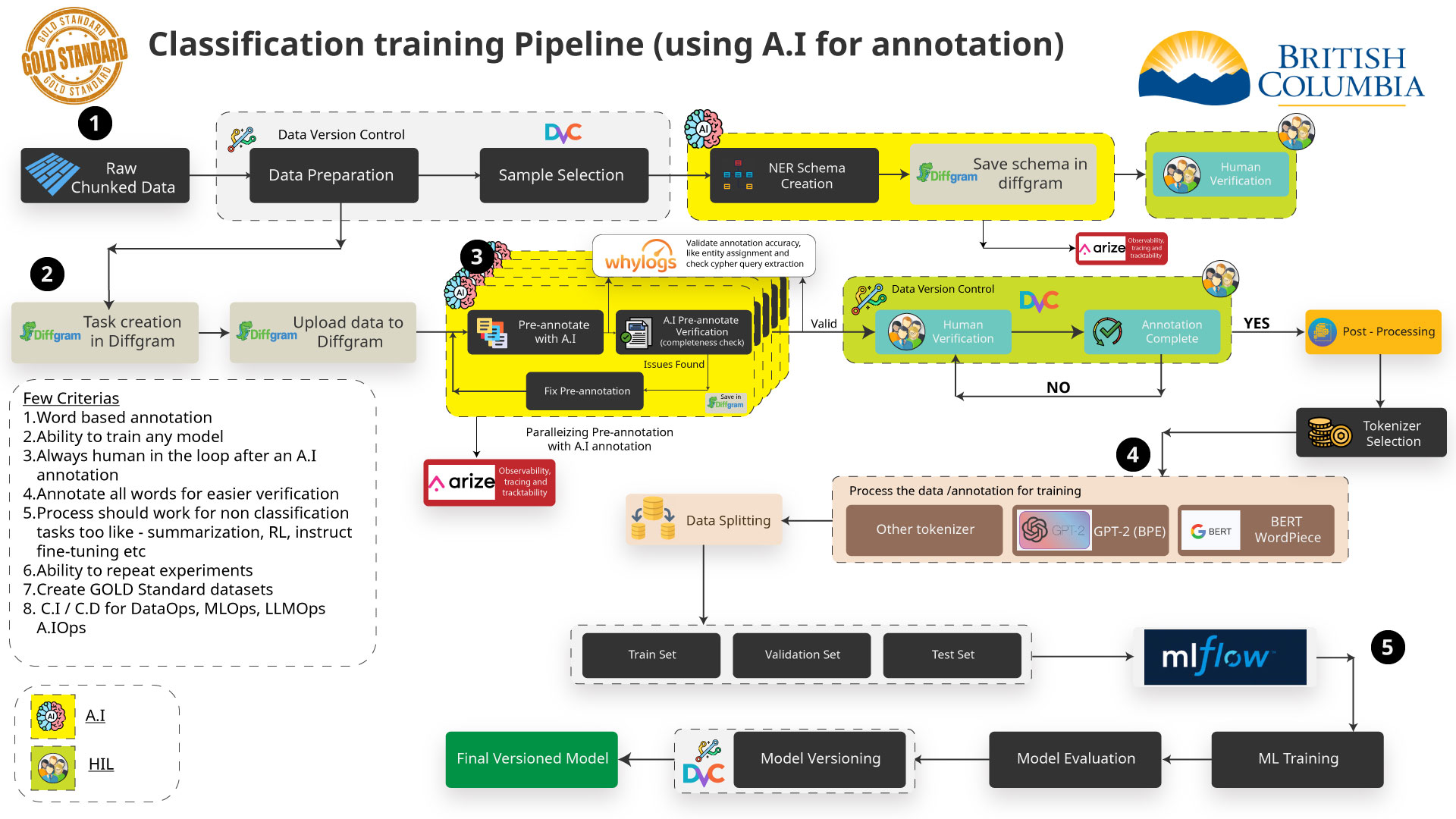
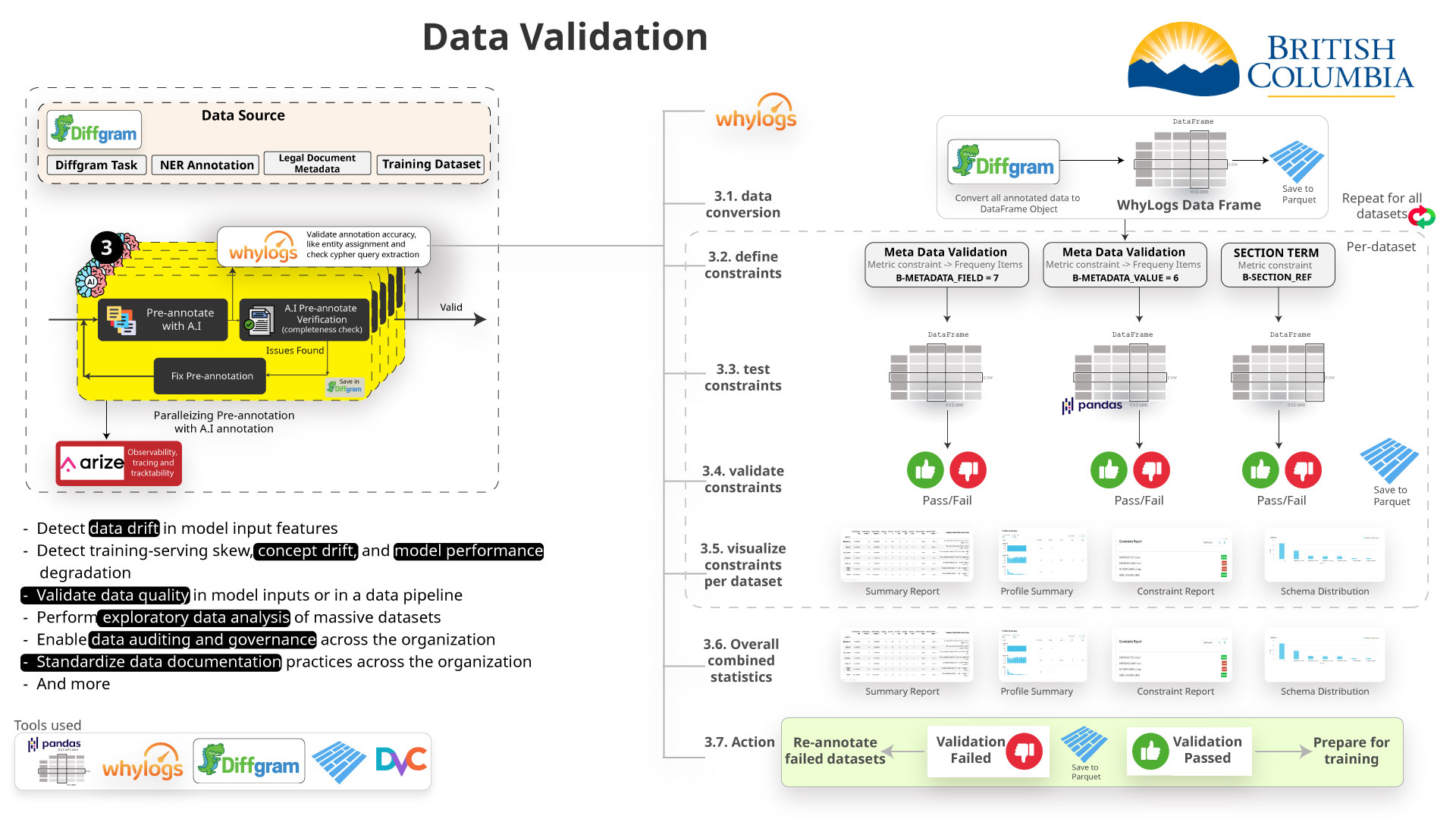
Human in the Loop
To improve the AI model we need to annotate and format the data properly. After the data is annotated we can use it to train the different models.
Embedding Adaptors
If the top sources are not accurate we can retrain the embedding model based on human feedback.
Data Annotation (NER)
For improving our retrieval and enhancing our result we are using an AI technique called NER (Named Entity Recognition) to annotate the data.
This can be done manually with tools such as Diffgram or Doccano or can be automated using an AI model to pre-annotate.
Doccano
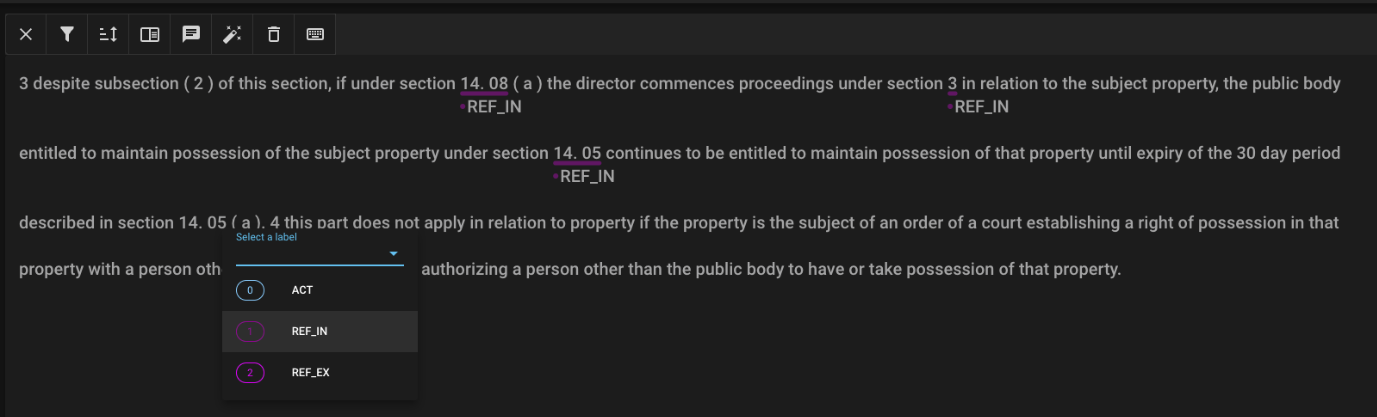
Assisted Annotation Process
- Need large amounts of training data. Initial results suggest thousands of samples would be needed for reliable results.
- Manually annotating this data takes people resources, but AI annotation is less accurate. For 5000 records:
- Manually: 8-10 days with high accuracy.
- Automated with generative AI: only hours but is not accurate so far.
Deep Research
Using artificial intelligence, specifically large language models, to conduct autonomous, in-depth, multi-step research.
Initial Research Experiment
Public Cloud
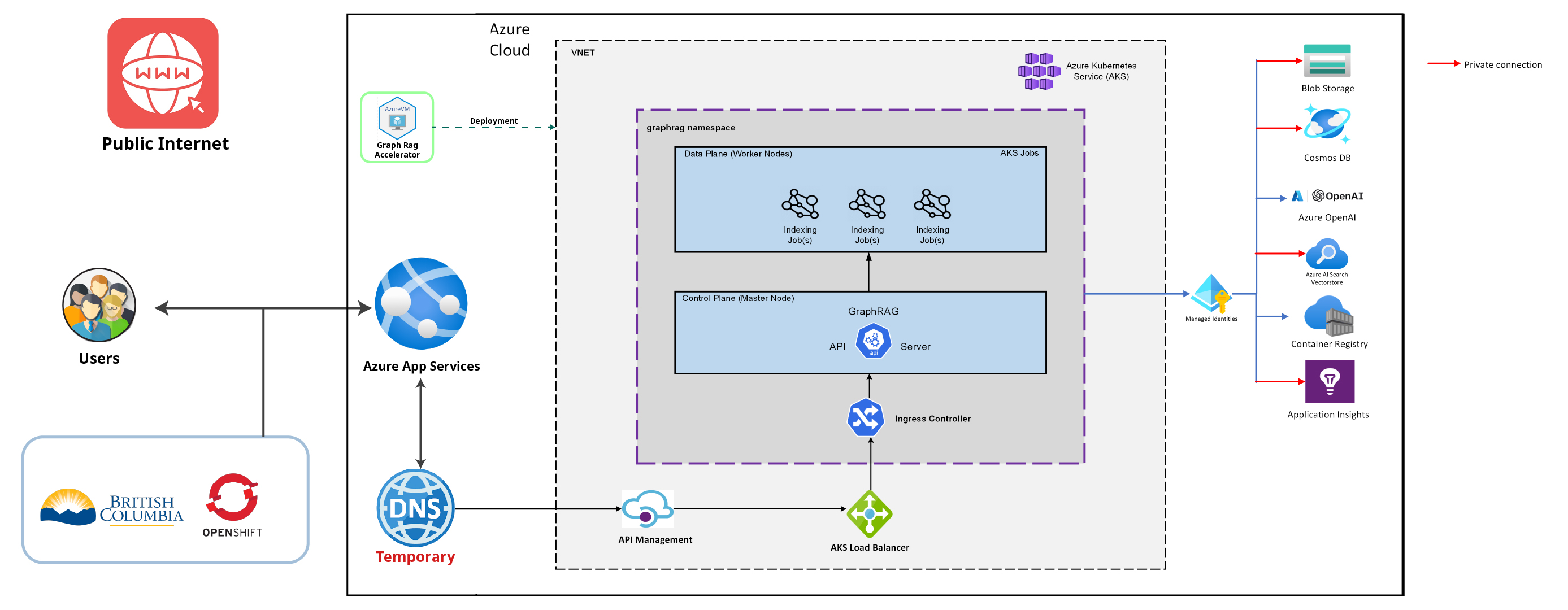
Challenges
- Getting this running in openshift and public cloud
- Having a good understanding of the data, the AI algorithms, AI workflows and performance compute is key
Q&A
Questions?
All of our presentation and diagrams can be found in our github repository.